Os sinais de ouro na engenharia de confiabilidade
Um pouco de história
Engenharia de confiabilidade está bem popular hoje em dia, principalmente depois que o livro de SRE do Google foi lançado e várias empresas começaram a adotar da sua própria maneira o conceito criado no início dos anos 2000.
Para quem já leu esse livro de cabo a rabo, provavelmente já conhece essas sinais de ouro ou golden signals, porém no que eles diferem de métricas tradicionais como utilização de CPU ou RAM? E como podemos evitar aquele SPAM de alertas e realizar um troubleshoot mais efetivo?
O que são esses sinais de ouro?
Podemos dizer que existem três métodos bastante utilizados atualmente para definir quais métricas devemos monitorar: A USE do Brendan Gregg, que mensura utilização, saturação e erros, que pode ser mais utilizada mais recursos internos. O RED do Tom Wilkie, que mensura taxa, erros e duração, que é mais apropriada para o ponto de vista externo, como requisições por exemplo. E a de SRE do Google, que mensura latência, tráfego, erros e saturação
Essa sobreposição entre as metodologias não é a toa, elas são relacionadas e também se complementam. Irei abordar cinco sinais (ou métricas) aqui:
- Rate -> Taxa de requisições medidas em
requests/sec - Errors -> Taxa de erros medido em
errors/sec - Latency -> Tempo de resposta e tempo de queue/wait e geralmente medido em ms.
- Utilization -> O quão ocupado aquele recurso ou aplicação está e geralmente é medido em porcentagem de 0 a 100%.
- Saturation -> O quanto um recurso ou aplicação está sobrecarregada, pode ser relacionado a utilização, mas é medido de
forma mais direta como queue depth ou concorrência. Geralmente essas métricas são medidas em
counter.
Fazendo um breve exercício, requests HTTP podem ser divididas entre status code (200, 3xx, 4xx, 5xx), assim como latency ou rate podem ser mostradas por URL.
Importante lembrar que essas métricas são para recursos que afetam diretamente no usuário final ou partes cruciais de uma aplicação, ou seja, são métricas que realmente importam se comparadas como utilização de CPU, RAM, rede, disco e etc...
Legal, mas como utilizá-los?
Nós fazemos a coleta dessas métricas chaves pensando em:
- Alertas, para informar sempre que há algo errado
- Troubleshoot, para ajudar a encontrar um problema
- Capacity planning e tuning, para melhorar aplicações, serviços e etc...
Média ou Percentil?
Quando falamos de alertas, geralmente eles são baseados na média, o que é um problema já eles são muito "sensíveis" a valores fora da curva e com certeza irá nos enganar. Por isso, é sempre bom criá-los com base em percentis.
Isso pode ser um pouco difícil de entender inicialmente, mas vou tentar explicar. Vamos levar o seguinte gráfico em consideração:
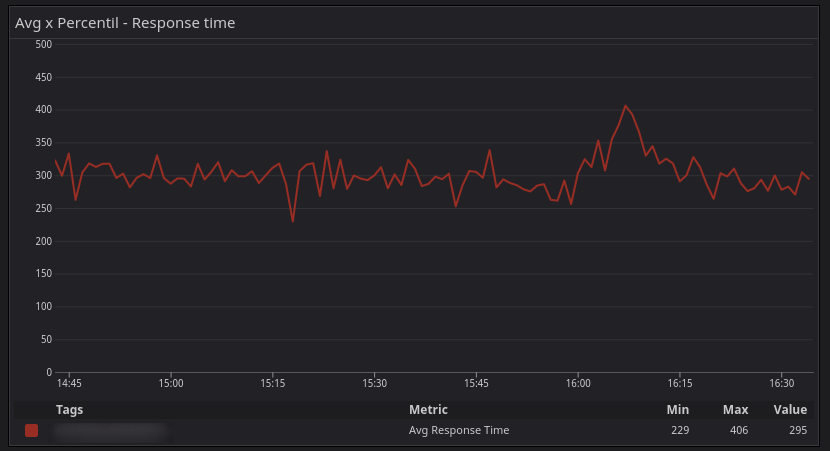
Não parece ser tão ruim né? O tempo de resposta está em torno de 300ms e sobe para 400ms por um momento. Porém a realidade muda quando incluímos o percentil 99
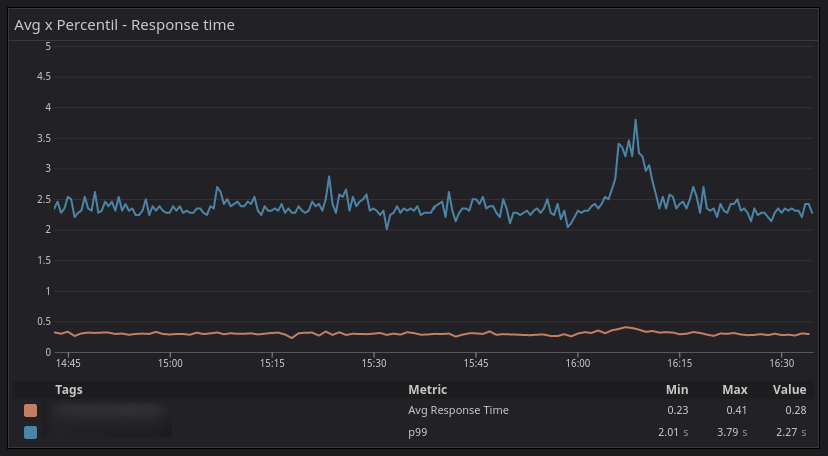
A linha alaranjada é a média do tempo de resposta e a linha azul é a latência p99. Por volta das 16:10 a média nos diz que está em torno de 400ms, porém o percentil 99 nos mostra que 99% das requests estão abaixo de 3.79s, ou seja, 1% dos usuário estão com uma péssima experiência nesse serviço.
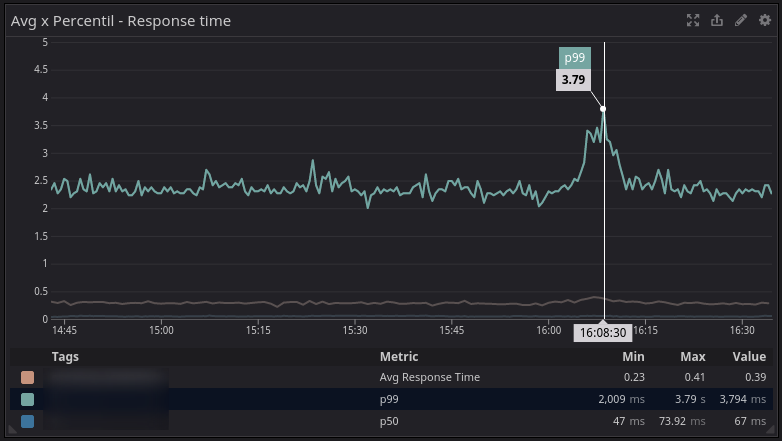
A média não condiz com a realidade, para chegar nesses 300ms, os pontos de latência coletados naquele minuto (ou segundo, vai depender da config da ferramenta) foram somados e divididos pela quantidade de amostras. No gráfico abaixo, podemos constatar que 50% dos usuários (p50) estavam com uma ótima experiência, onde a latência está em 67ms.
Enriquecendo informações
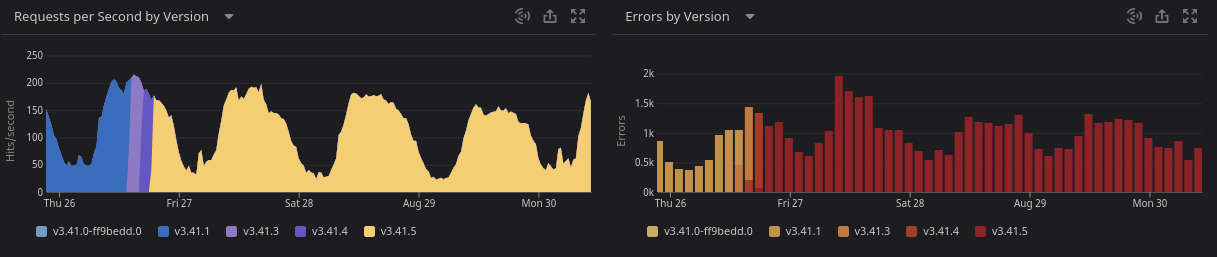
Algo que é um pouco mais chato de fazer, mas que ajuda muito é usar tags ou correlacionar eventos a suas métricas, como deploys, eventos de auto scaling, restarts e etc. Nas imagens abaixo temos alguns comparativos da quantidade de requests e erros entre versões diferentes da mesma aplicação.

Troubleshooting
Correlacionar problemas com esses eventos que ocorrem facilita muito o dia dia. Obviamente, ainda é necessário ligar muitos pontos, porém a dica que fica é, instrumente e colete dados de tudo que for possível, ainda mais quando trabalhamos com sistemas distribuídos, o que vai ajudar a mapear dependências e trabalhar em melhorias onde realmente importa.
No exemplo abaixo, temos um pedaço de um trace distribuído entre uma aplicação monolítica e uma função serverless e o tempo de execução de cada serviço nesse trace.
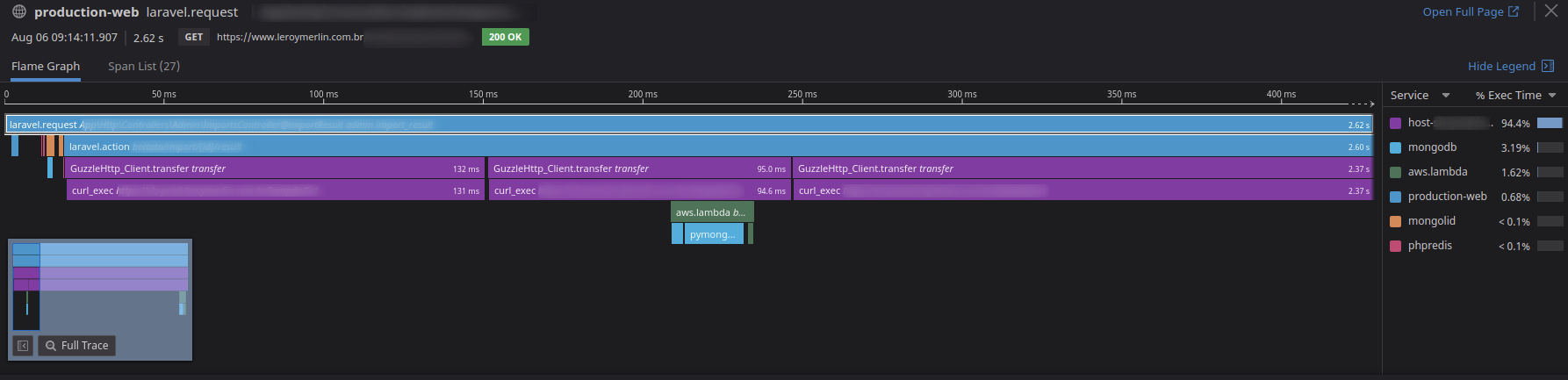
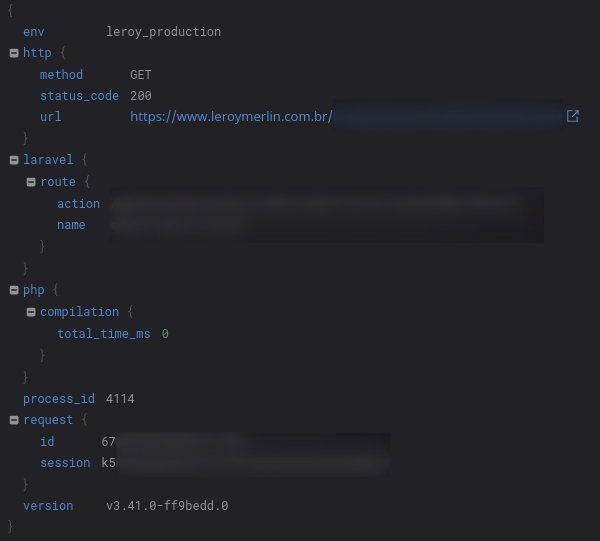
E para cada span desse trace, temos informações diferentes relacionadas a logs, métricas do host ou da função e as tags, como versão e id da request.

Próximos passos e o que vem por aí
Nessa série de posts, pretendo continuar abordando assuntos relacionados a SRE de uma forma simples e como trabalhamos aqui na Leroy Merlin.
Fiquem ligados! :)